
RAG RAG on the Wall.
The post explains Basic RAG used in mid-late 2023 to Advance SoTA RAG architecture used currently. Multiple improvements incoming

Every organization has their own private data that they need to incorporate into their AI apps, and a predominant pattern to do so has emerged, retrieval augmented generation, or RAG. Successful AI apps aren’t built directly on top of LLMs, they’re being built on top of AI systems. These systems come with additional functionalities, including retrieval capabilities to support RAG.
In order to build robust retrieval capabilities, teams need a production-ready data pipeline platform that can extract data from multimodal sources, clean, transform, enrich, and distribute data at the right time and in the right form. In the case of RAG-based apps, that right form is usually vector embeddings, a data representation that carries within it semantic information that was generated during model training.
Enhancing RAG
In basic RAG pipelines, we embed a big text chunk for retrieval, and this exact same chunk is used for synthesis. But sometimes embedding and retrieving big text chunks leads to suboptimal results. For example, there might be irrelevant details in a big chunk that obscures its semantic content, causing it to be skipped during retrieval. What if we could embed and retrieve based on smaller, more semantically precise chunks, but still provide sufficient context for the LLM to synthesize a high-quality response? This is an advanced RAG pattern known as “Small-to-Big”
Currently there are two basic patterns for implementing RAG
Pattern 1 – Large Chunks: In base case, queries are run and synthesized against large chunks of text.
Pattern 2 – Small Chunks: Similar to the base case but the chunks sizes that have been tuned to be much smaller.
When the chunks are large we have a larger context to have good synthesis of responses but our recall is less specific and may miss returning the most relevant text. For small chunks we have the reversed problem. The recall is more accurate for certain queries but sometimes we don’t have enough text available to generate a proper response.
The root problem is we are using the same data for both querying and synthesis. If there was a way to decouple them, we could conceivably get better results. This is where the RAG pattern known as “Small-to-Big” comes in. The idea is to run queries across small chunks of data, but run synthesis over large chunks of data. Each small chunk of data we query will then link back to a large chunk of text which is used for synthesis. Ideally this should give us the best of both worlds.
Sample Notebook - https://colab.research.google.com/drive/1AvPpRvzLvGPMG3vVgcRDOvSdar_lsTks
Summary
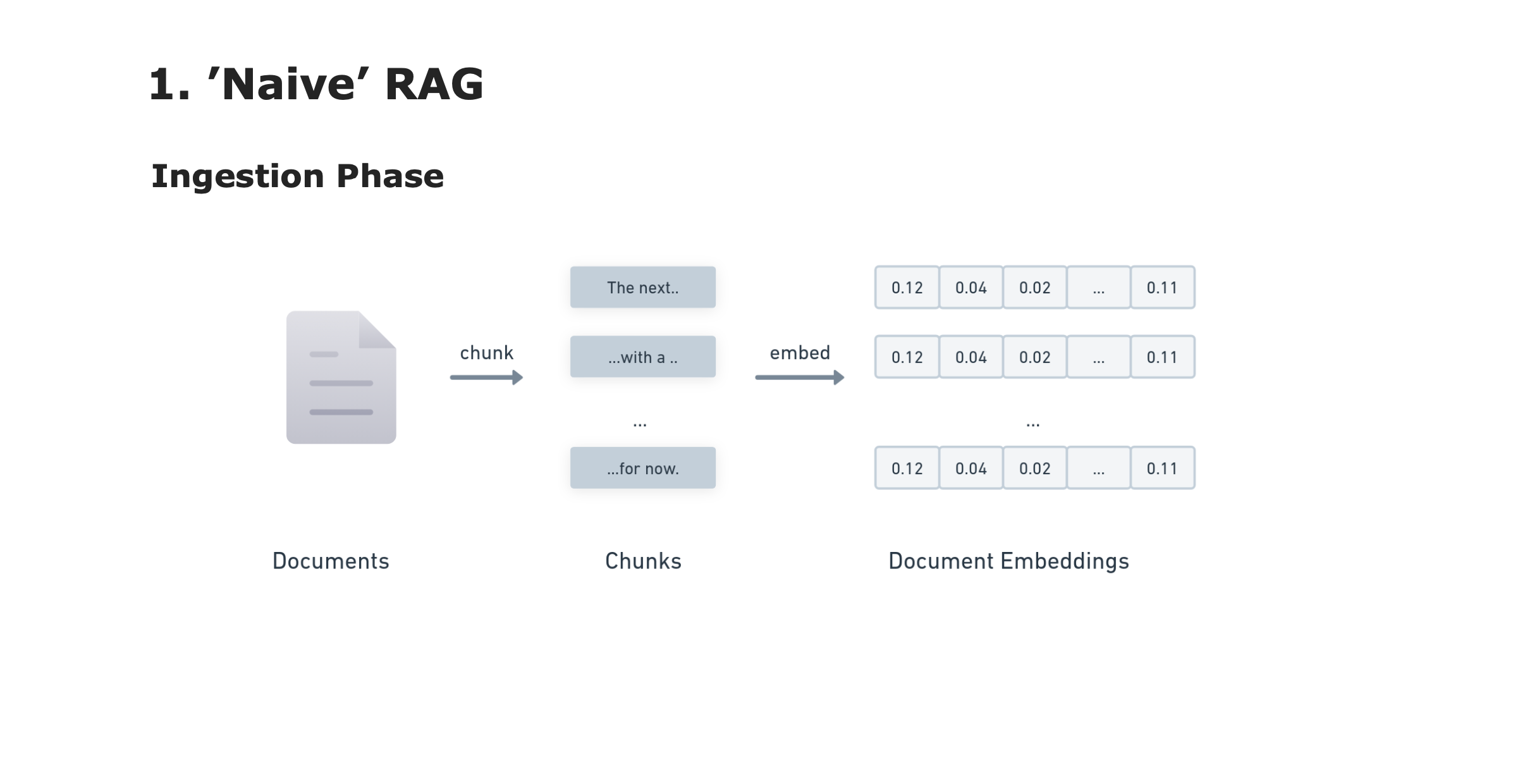
Basic RAG
Ingestion Phase - Documents are chunked and embedded
Retrieval Phase - User query is embedded and the top-k chunks are retrieved.
Advance (Small-to-big) RAG
Ingestion Phase - We decouple the text chunks to be embedded in the vector database (passage text chunks) from the text that will be used in the LLM context (context text chunk).
There are various approaches possible for processing documents and decoupling, in particular:
• ParentDocument
• Summary
• RecursiveRetrieval
• Small to Big Retrieval
Retrieval Phase - Instead of directly embedding the user query, we transform it into multiple search queries, that are then embedded and used for the vector similarity search.
Here again, there are multiple approaches for this transformation, in particular:
• MultiQuery
• Rephrasing
• Hypothetical Document embedding (HyDE)
• Step-back prompting
We retrieve the top-k most similar document embeddings (based on the passage text) for every search query.
We use a reranker to rerank all the vector search results based on the passage text to keep the top-n passages. Finally, we get the context text associated to each top-n passage to build the final context for the LLM.





References
https://datavolo.io/2024/03/data-engineering-for-advanced-rag-small-to-big-with-pinecone-langchain-and-datavolo/
https://www.linkedin.com/posts/lidia-pierre_advanced-rag-techniques-activity-7187412185449488384-9tnm?utm_source=share&utm_medium=member_desktop